Angular
C#
TypeScript
After nearly a year, another project comes to its completion. Since the beginning of my master’s degree, we were given a project in collaboration with
Domeba – a global powerhouse when it comes to compliance software.
Given the somewhat sensitive nature of the work, I won’t be sharing technical details or deeper conceptual insights. Instead, I simply want to mark this milestone and reflect on the experience of seeing a long-term project through to completion once again.
My Role
The project itself was, in many ways, an experiment – the first of its kind – bringing together students from both the master’s and bachelor’s program on a single project. As mentioned above, the project was requested and supervised by Domeba GmbH, who had developed an innovative idea they wanted us to bring to life, in form of a proof of concept. For our professors, however, the main goal was our own growth and experience. They wanted us to develop the skills necessary to operate at the level of an industry professional worthy of a master’s degree and to learn how to collaborate effectively with other developers while maintaining a leadership role.
For us, this meant two main objectives. First, we had to guide the bachelor students – keeping them motivated, on track with the project and helping them acquire valuable skills along the way. Second, we were responsible for ensuring that Domeba’s vision was realized and delivered successfully.
To better manage the larger team and improve our efficiency on smaller tasks, we split the group into four smaller teams, each consisting of around four developers. One team had a stronger focus on project management and took responsibility for overseeing the project as a whole, while the other teams organized themselves internally to handle their respective tasks. Later on, once most of the basic functions where implemented, we shifted away from the team structure and adopted a more task-based system, where everyone worked independently on smaller individual tasks.
Within my team, I initially took on the role of a backend developer, primarily working with .NET. Once the backend was mostly complete, my role shifted to a more intermediary position, integrating the backend structure into the frontend. This marked my first real experience with Angular and TypeScript development.
In addition to my team responsibilities, I also took on a project-wide role akin to a pipeline engineer. At the start of the project, I was responsible for setting up guidelines and rules for coding standards, version control and internal pipelines. Once development began and all developers started using pull requests, my role expanded to reviewing every PR to ensure that guidelines were followed and that the code would not compromise the current build. While maintaining our repository according to these standards, I also ensured that, by the end of the project, all files and the repository were properly organized and ready to be handed over.
Challenges
Over the course of the project, we faced countless challenges – more than I could possibly cover here. Still, I would like to highlight some of the most notable ones I was involved in.
Our team, consisting of one other master’s student, two bachelor students and myself, was broadly tasked with extracting data from text files. Sounds simple? That’s what we thought too. It turned out to be far more complex than we expected.
These were no ordinary text files, they included HTML, JSON, XML and more. Extracting the raw content was not at all too difficult. But the real challenge arose when we needed to preserve the structure of the text, like deciding what counts as a headline, a paragraph or another structural element. For HTML, this is straightforward, you can simply read the tags. But what about other structural layers that are not explicitly marked?
Our first major task was to define what structural layers exist and how they should be represented. Take a paragraph of text, for example – this could be considered layer one. A bullet point inside that paragraph could be layer two, but what if the bullet itself contains numbered content? Should that be layer two or layer three? We aimed to represent any text in a form with clear, distinct structural layers that could represent the content of a text file while preserving the hierarchical relationships between elements.
This system, for example, makes it possible to treat citations as an independent, or more precisely, semantic-structural layer. Since a citation always refers to a piece of text, defining its structure allows us to establish a hierarchical relationship between the paragraph and the citation. In this way, the citation becomes a distinct object separate from the main text. Each structural element then contains the content that truly belongs to that specific layer, making the hierarchy both clear and precise.
With the basic concept in place, we now faced the challenge of implementing a system that could reliably extract this structural hierarchy from any text file. “How do we do this?” was a question we asked ourselves repeatedly. Extracting headlines and other elements with clear HTML tags was straightforward, but text hidden in <div>s or other nested structures was much trickier.
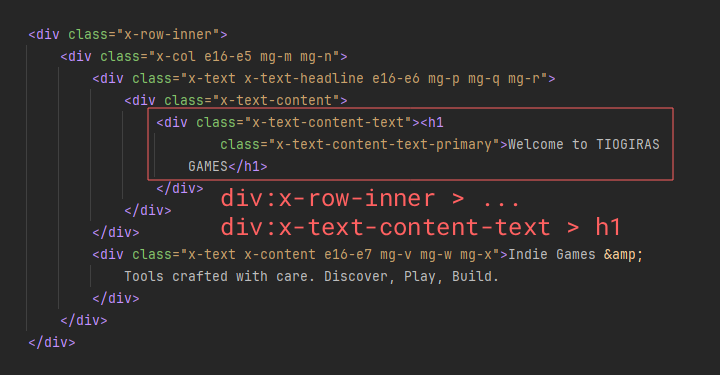
As we experimented with HTML files, we had a breakthrough. Instead of treating elements in isolation, we could address them based on their hierarchical position, similar to using CSS selectors to target specific content.
After much trial and error, we developed a method to reference individual structural elements based on their relative position to other elements.
This approach turned out to be highly versatile. It could be applied not only to HTML but also to JSON and XML files. By the end of this phase, our team had achieved a system capable of confidently extracting any text from structured text files while preserving its hierarchical structure.
The Real Challenges
Notice how I used the term “structured text files” earlier? One of Domeba’s major objectives for the project was that our text extraction system also needed to work with unstructured formats, like PDFs. With the basic concept in place, out team spent the rest of the first half of the project exploring how to integrate PDFs into the system.
The main challenge with PDFs is that they contain no inherent structure – no tags, no class names, just raw text. I can’t reveal the exact method we used to incorporate PDFs, as it was an integral part of the system we delivered. What I can say, is that developing this capability took almost as much time as planning and implementing the system for structured file formats. By the end of the first half of the project, we had a working prototype capable of extracting content from pre-selected PDFs.
In the second half, while my fellow master’s student focused on a machine learning approach to enhance our extraction process, my role was to ensure the system could handle any PDF, not just the pre-selected ones. This turned out to be the most trial-and-error heavy part of the project. Solving one PDF’s issues often revealed a new edge case in another file. Each case required implementing new features, from detecting page layouts, to combining bullet points with their corresponding text based on spacing, to identifying layout changes within a page or calculating the correct reading order of text.
Despite the countless edge cases, we ultimately delivered a system capable of handling most text-based PDFs with remarkable accuracy and reliability.
But why would you need something like this? In short, it is a powerful tool that serves as the foundation for features we can and did built on top of it. For example, with this system we could easily extract meta information such as release dates from blog posts or author names and titles, even if they are not explicitly marked as such.
Real Industry Experience
In my opinion, the project did an excellent job of giving us valuable insight into what it is like to work with an actual industry partner. It simulated the realities of future professional work remarkably well.
We held regular presentations and meetings where we had to justify and present our progress, often negotiating around newly introduced requirements. Through this, I believe we all learned an important lesson in how to find a balanced middle ground between aiming for the best possible outcome and staying realistic within the limits of time and resources.
Domeba GmbH deserves special recognition here. They entrusted us with responsibility while at the same time giving us the freedom to approach problems in our own way. They were consistently kind, approachable and professional. Working with them was a truly remarkable experience.

Image Source: Domeba GmbH (https://www.linkedin.com/posts/domeba-gmbh_im-rahmen-einer-gemeinsamen-kooperation-haben-activity-7358441430819708928-zKy2)
With all its ups and downs and the many challenges we faced, it was certainly an intense project. Yet, I am deeply grateful to our professors, supervisors and Domeba for making it possible to gain a first hand experience of what working in the industry might feel like once I complete my master’s degree.